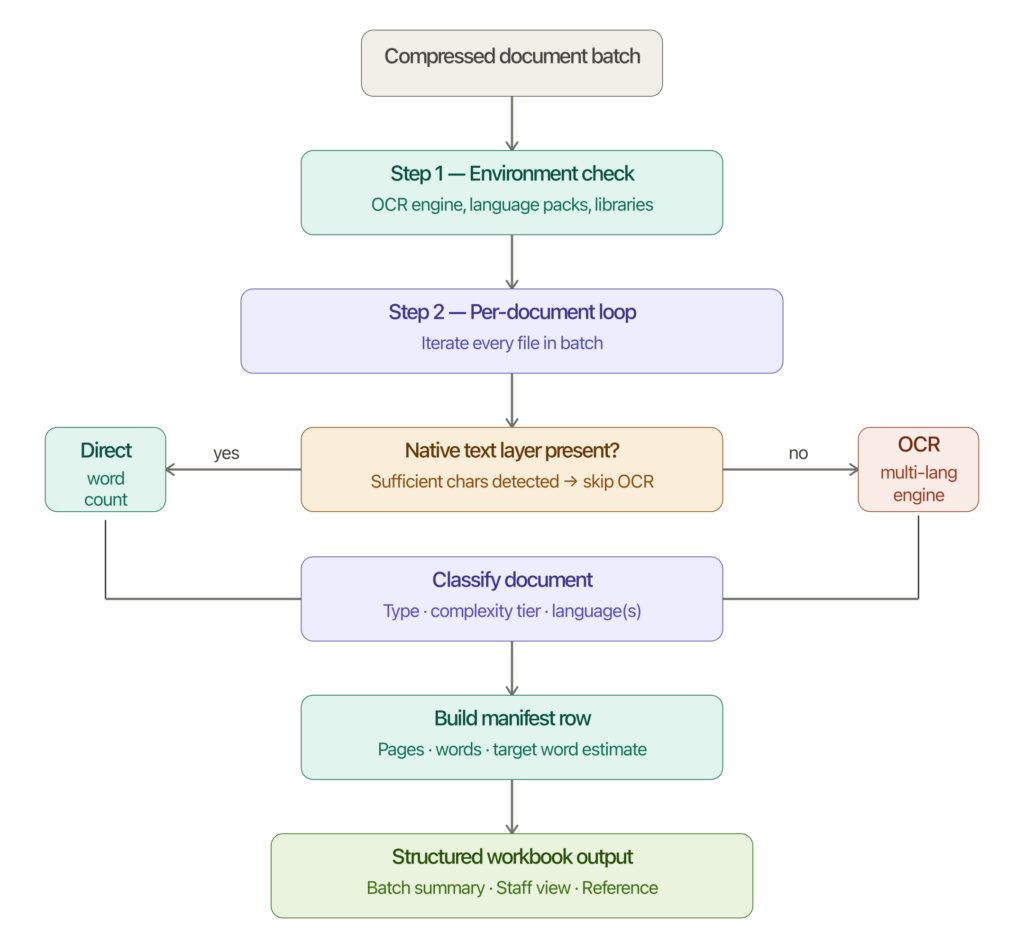
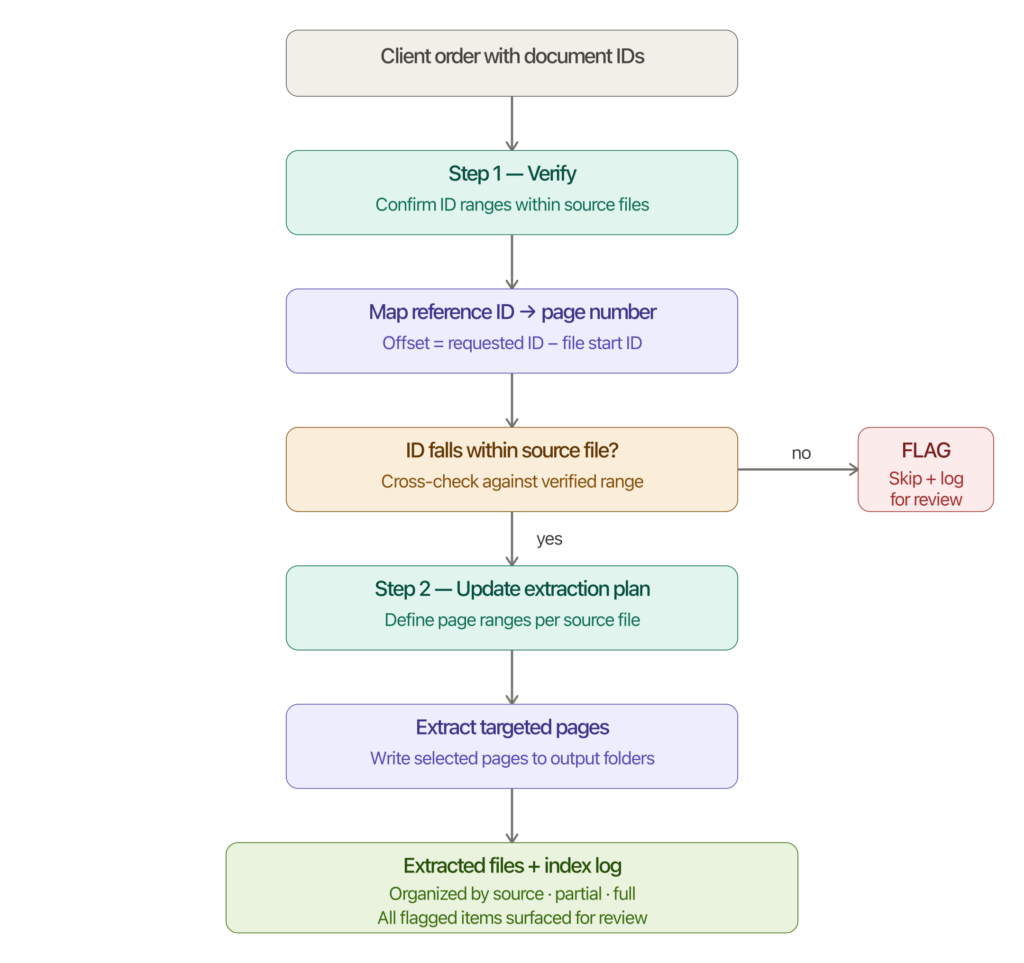
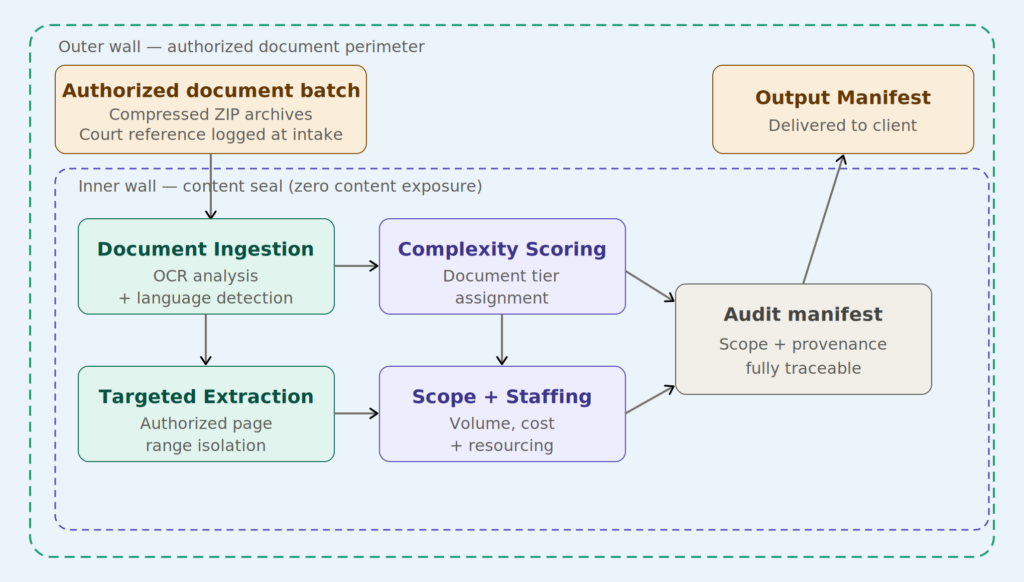
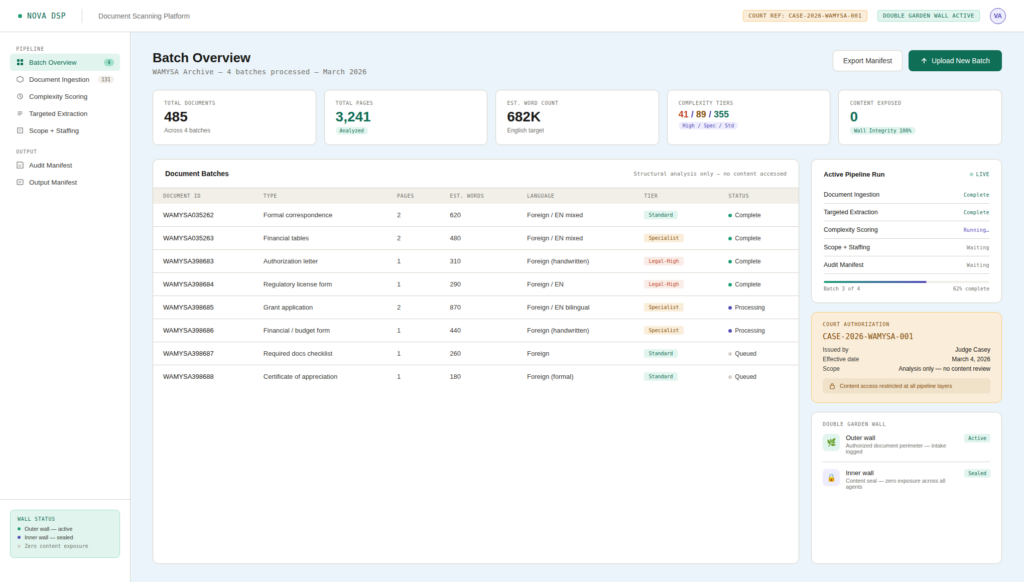
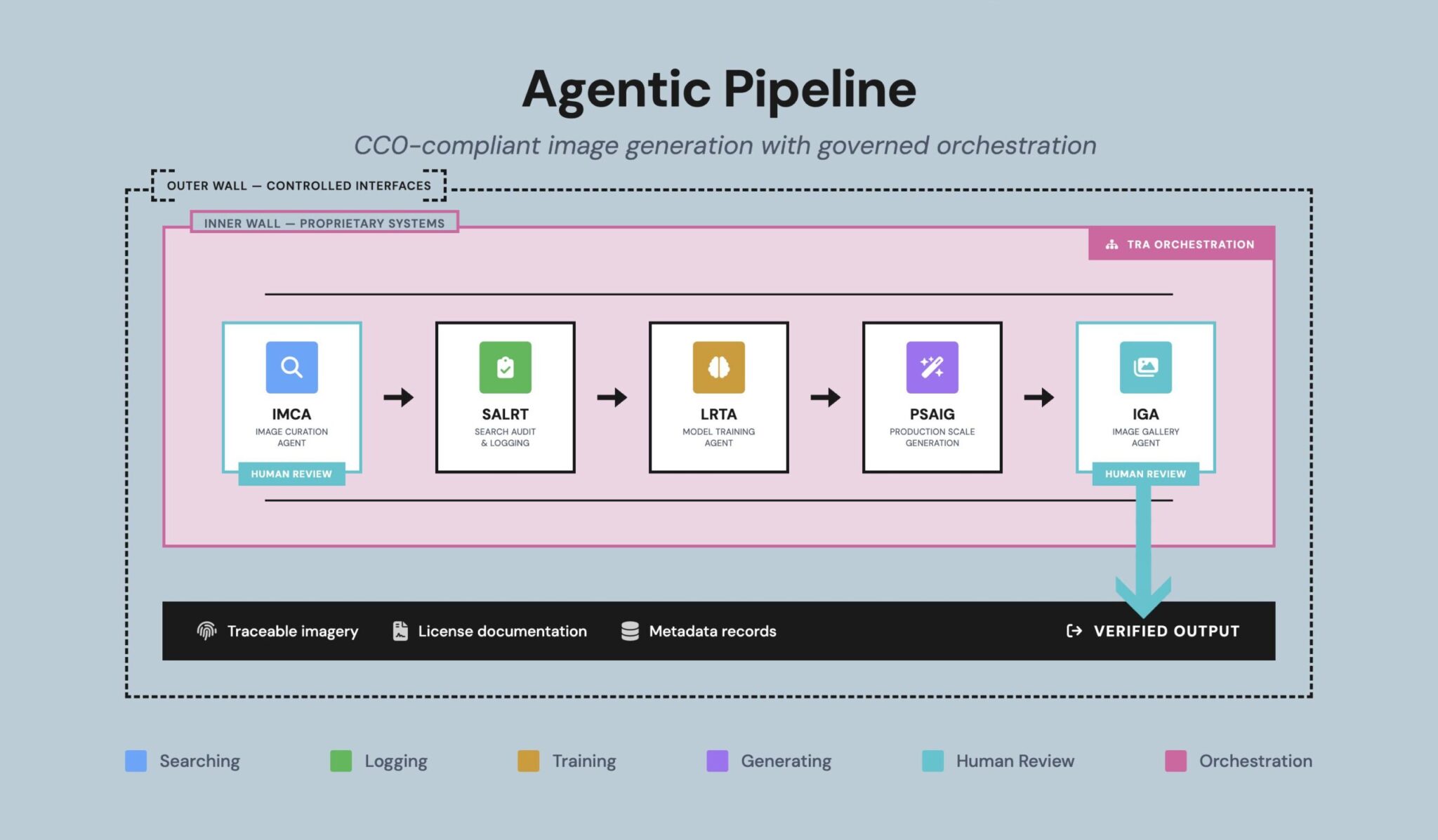
When your agents can’t prove they’re trustworthy, your business can’t either.
Everyone is racing to build smarter AI agents. Fewer people are asking the harder question: once we have trillions of them, how do they find each other, verify each other’s credentials, and collaborate without tearing the whole system apart?
Sandeep Mahendru – an Engineering Leader and Senior System Architect at Google, where he builds AI-driven solutions for the financial market – recently published a piece on Medium that lays out the clearest architecture I’ve seen for answering that question. It’s called Proposal for the Global Backbone of the Agentic Web, and it’s worth a careful read.
“We are currently building millions of specialized agents, yet we have no global address book to find them, no shared language to verify their skills, and no scalable security layer to ensure they aren’t actively sabotaging our workflows.”
I am walking through it in this post as it maps to work we’ve been doing at Velocity Ascent – and because the ideas in it have real consequences for anyone thinking seriously about where enterprise AI is heading.

The “Wild West” Moment
Sandeep opens with a frame I find hard to argue with:
“We are currently building millions of specialized agents, yet we have no global address book to find them, no shared language to verify their skills, and no scalable security layer to ensure they aren’t actively sabotaging our workflows.”
This is the gap. It’s not a technical gap in the narrow sense – the individual pieces exist. Large language models are remarkable. Agent frameworks are maturing. But the connective tissue between agents – the infrastructure that makes a network of agents trustworthy and useful rather than just chaotic – doesn’t yet exist at scale.
Sandeep calls this the “Cisco Moment” of the Agentic Web. The analogy is deliberate: the winners in the next era of AI won’t be defined by who builds the smartest model. They’ll be defined by who builds the backbone; the discovery, routing, and trust layer – that lets trillions of specialized agents find and work with each other safely.
* A “Cisco moment” is a stock market analogy referring to the dot-com era when networking giant Cisco Systems saw its stock plummet roughly 80% after telecom companies stopped buying its hardware. Today, financial analysts use the term to warn that massive capital expenditures in AI might create a similar bubble, particularly drawing parallels between Cisco in 2000 and Nvidia today. [1, 2, 3, 4]

From Code-First to Intent-First
The shift Sandeep describes isn’t just infrastructural – it’s epistemological.
Traditional software development is code-first. A developer translates a goal into explicit instructions, one procedure at a time. What’s emerging is intent-first orchestration: you describe what you want, and an underlying intelligent infrastructure figures out which combination of specialized agents can execute it.
“Instead of building monolithic software silos, developers are now focused on defining high-level goals that are executed by a ‘quilt’ of autonomous, specialized agents.”
The “quilt” metaphor is worth sitting with. Not a single God Model that does everything, but a federated patchwork of best-in-class experts – each sovereign, each specialized, each discoverable. The question is how you stitch them together in real time.
That stitching mechanism is what Sandeep calls the Brain.

The Brain: Semantic Intent Parsing at Scale
The Brain is the orchestration intelligence at the center of this architecture. Think of it less like a search engine and more like a very sophisticated dispatcher.
Traditional keyword search is too blunt for this. If a user’s request is “help me optimize our supply chain for Q4,” a keyword search returns documents. An intelligent Brain decomposes that intent into a structured, multi-agent workflow – logistics expert, finance agent, demand forecasting agent – and routes each sub-task to the best available specialist in real time.
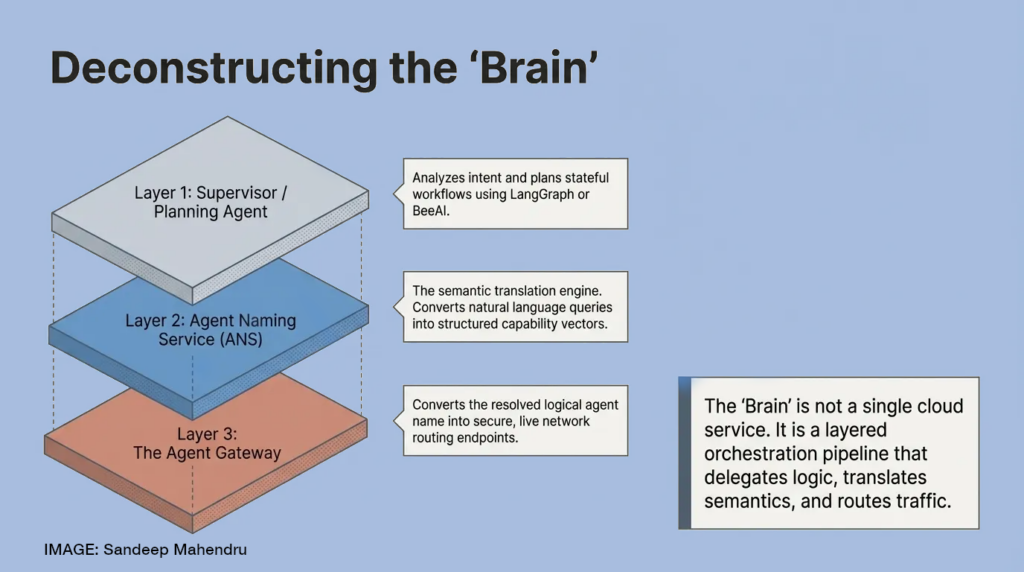
Critically, Sandeep argues against a centralized bottleneck architecture:
“A standardized metadata routing protocol allows secure, local orchestrators to decompose human requests into multi-agent workflows while maintaining strict context isolation.”
This is a subtle but important design principle. Discovery doesn’t have to be centralized to be powerful. A federated model, where a lightweight metadata layer indexes agent capabilities across independently governed registries, can be both scalable and resilient.

The Discovery Gap: Why Agent Cards Aren’t Enough
The current standard for agent interoperability is A2A (Agent-to-Agent protocol), which gives every agent a structured “Agent Card” – essentially a business card declaring its capabilities, authentication requirements, and communication standards. A2A is built on established web infrastructure: JSON-RPC 2.0 over HTTP/S, OAuth 2.0, mTLS. It’s solid, enterprise-grade, and open.
But Agent Cards are self-declared. And self-declaration, as anyone who’s reviewed a vendor pitch deck knows, is not the same as verified performance.
AgentFacts: Report Cards, Not Business Cards
“Trust is no longer a ‘claim’ or a static audit; it’s an audited metric signed by third-party authorities and constantly tested via automated prompting and local consensus.”
AgentFacts are the proposed evolution beyond Agent Cards. Where an Agent Card says “I am a financial analysis agent,” an AgentFact is a cryptographically signed, W3C Verifiable Credential that says “this agent has been independently audited, has completed 12,000 successful tasks with a 97.3% accuracy rate, and has zero confirmed hallucinations in regulated output contexts.”
The distinction matters enormously in enterprise settings. When an agent is making decisions that touch compliance, financial transactions, or patient care, “trust me, I’m good at this” is not an acceptable credential.

Byzantine Fault Tolerance: In-Flight Security
Even cryptographically signed AgentFacts don’t solve the full security problem. Sandeep’s architecture adds a layer that I think most people building in this space haven’t adequately grappled with: Byzantine Fault Tolerance.
The analogy in the piece is the best summary I can offer:
“A Secure Federated Registry is like a ‘No Fly List’ – it keeps known bad actors out. But Byzantine Fault Tolerance is like ‘In-Flight Security’ – it protects the passengers even if someone with a valid ticket turns out to be a threat.”
BFT, in this context, means triangulating outputs across multiple independent agents and using quorum voting to detect when a “trusted” actor is hallucinating, has been compromised, or is simply wrong. Because traditional consensus mechanisms add latency, Sandeep proposes economic staking and slashing as the enforcement layer – agents put something at risk when they participate, and bad actors lose it.
This is crypto-native thinking applied to AI infrastructure. Whether or not you have a background in distributed systems, the principle is intuitive: skin in the game changes behavior.
Cognitive Liquidity: The AI-NPM Model
The long-term economic vision Sandeep lays out is what he calls Cognitive Liquidity – the ability to “import” verified intelligence as easily as a developer imports a software library today.
“By integrating discovered agents directly into low-code environments… developers can ‘import’ verified intelligence as easily as they import software libraries today.”
This is the AI-NPM model. Just as npm transformed software development by making reusable, versioned, community-maintained code packages trivially accessible, a mature Agentic Web would make reusable, verifiable, audited AI capabilities trivially accessible – streamable on demand, licensed transparently, and composable into complex workflows without custom integration work.
The infrastructure question isn’t just technical. It’s economic. Whoever builds the registry, the Brain, and the trust layer controls the tollbooth for an enormous amount of future AI commerce.
* In the context of AI, NPM (Node Package Manager) primarily refers to its role as the distribution hub for AI developer tools, libraries, and autonomous agents. While originally built for JavaScript, it has evolved into a “universal distribution platform” for the AI ecosystem.

Open Standards and the Public Good Mandate
One of the most important arguments in the piece is the one Sandeep makes almost as a footnote: this infrastructure needs to be governed by neutral bodies, not owned by any single platform.
A2A is already moving in this direction through the Linux Foundation and related open standard initiatives. NANDA – the Naming and Discovery Architecture – is one of the projects building the federated registry layer. If any single company owns the “Global Address Book,” the network effect becomes a chokehold. Open governance is the only model that scales without creating the kind of rent-extraction that would strangle the ecosystem before it matures.
A Note on Where This Work Lives
Sandeep Mahendru and I are both members of the NYC Chapter of the NANDA Project, an initiative out of MIT Media Lab focused on building the open naming and discovery layer for the Agentic Web. The work Sandeep describes isn’t purely theoretical – it’s the kind of architecture we’re actively thinking about in that community, and it’s influencing real infrastructure decisions being made right now.
The Agentic Web isn’t coming. It’s being built. The question is whether the backbone gets built right.

Why Agent Trust Matters to the C-Suite
If you’re a technology leader or founder thinking about AI strategy, Sandeep’s framework suggests a few reorienting questions:
- Are you building agents that will be discoverable by other agents? Or are you building another closed silo?
- How are you establishing verifiable trust in your AI outputs – not just internally, but in ways that external systems could validate?
- Are your AI investments positioned for the intent-first world, or optimized for the code-first world you’re leaving behind?
The companies that get this right early will have an enormous structural advantage. The backbone of the Agentic Web is being laid now, and the patterns being established will be hard to reverse.
Sandeep Mahendru’s original article, Proposal for the Global Backbone of the Agentic Web, is published on Medium. Sandeep is an Engineering Leader and Senior System Architect at Google, where he builds AI-driven innovative solutions for financial markets.
Joe Skopek is the founder of Velocity Ascent, an AI-first innovation consultancy based in New York. Both are part of the Leadership Team of the NYC Chapter of the NANDA Project from MIT Media Lab.