The future I sketched in 2024 is no longer hypothetical. It’s shipping, it’s backfiring, and it’s rewriting who wins.
A follow-up to “Fashion Tech: The Present Future of Fashion and Technology” (October 2024)
When I published that first piece in October 2024, I argued that the blend of fashion and artificial intelligence was creating “limitless possibilities.” Roughly eighteen months on, the possibilities are no longer hypothetical. They are shipping. They are also forcing the harder questions the original post only gestured at: not just whether we can generate a model, a garment, or a storefront, but whether we should, and on whose terms.
The original throughline still holds. I compared today’s AI tooling to the sewing machine of the 19th century, a technology that reshaped how fashion is made, marketed, and consumed, mostly by collapsing time and cost. That frame has aged well. What I underestimated was the speed of the collapse, and how quickly the conversation would shift from efficiency to ethics, labor, and trust.
Here is where things actually landed.
The trajectory I called: hyper-personalization went from edge to baseline
In 2024 I described hyper-personalization, virtual fitting rooms, and digital “Sketch-to-Storefront” workflows as the leading edge. They are now closer to table stakes. By early 2026, McKinsey’s fashion technology outlook put adoption of machine learning for trend forecasting, planning, and 3D sample generation at roughly 48% of global brands. The AI-generated fashion photography market, barely a line item when I was writing, grew from about $1.51 billion in 2024 to around $2.01 billion in 2025.
The design tools I singled out, Browzwear and Lalaland.ai, did not just survive; they matured into a connected pipeline. Browzwear’s framing for 2026 is “idea to twin to shelf,” with the same digital twin now feeding not only fit and production but AI-generated marketing imagery. Virtual sampling, by various industry estimates, now cuts sample-development cost by 60 to 70% and time-to-market by up to half. The “first physical sample is the only sample” pitch I quoted in the original has, for a lot of teams, simply become true.
The proof point is no longer a vendor demo. MAS Holdings, the apparel manufacturer behind many of the intimates, swimwear, and performance brands you already know, (Victoria’s Secret, Nike, lululemon) began its digital product creation push in 2017 and stood up a dedicated Centre of Excellence in 2020.
It now develops more than 4,000 unique 3D styles a year for over 50 brands, with real-time co-creation replacing rounds of physical samples. The faster lead times and lower fabric waste arrived as byproducts of integration, not as one-off stunts. That is the version of “Sketch-to-Storefront” I was describing in 2024, finally operating at industrial scale.
Shift one: the synthetic model walked out of the back office and onto the cover
In the first piece I treated AI imagery mostly as a production convenience. The technology has since become good enough to be indistinguishable from a photograph, and that is exactly where the trouble started.
Mango ran AI-generated models in a 2024 campaign, with its CEO defending the move on speed grounds. Levi’s tested AI models and then walked the messaging back, insisting it was not a diversity strategy and that live shoots would continue.
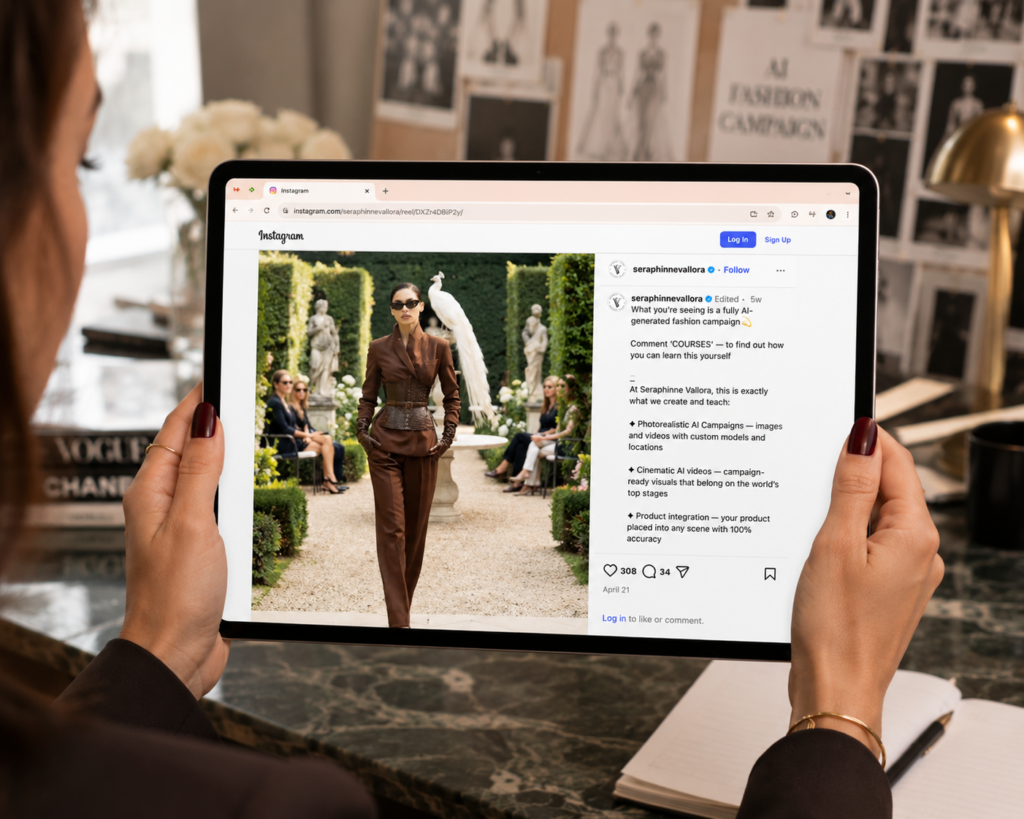
Then, in August 2025, a Guess advertisement in Vogue, produced by the AI studio Seraphinne Vallora, became a genuine firestorm. The images were polished enough to read as editorial photography; only a small disclaimer revealed the model did not exist. The backlash was loud, and it was not really about image quality. It was about disclosure, displaced creative labor, and the narrow, conventionally “perfect” definition of beauty that synthetic models tend to default toward.
Regulation moved in parallel. The EU AI Act, adopted in 2024 and rolling out through 2027, pushes toward disclosure of synthetic media, transparency around training data, and respect for intellectual property, even when the underlying tools are open-source.
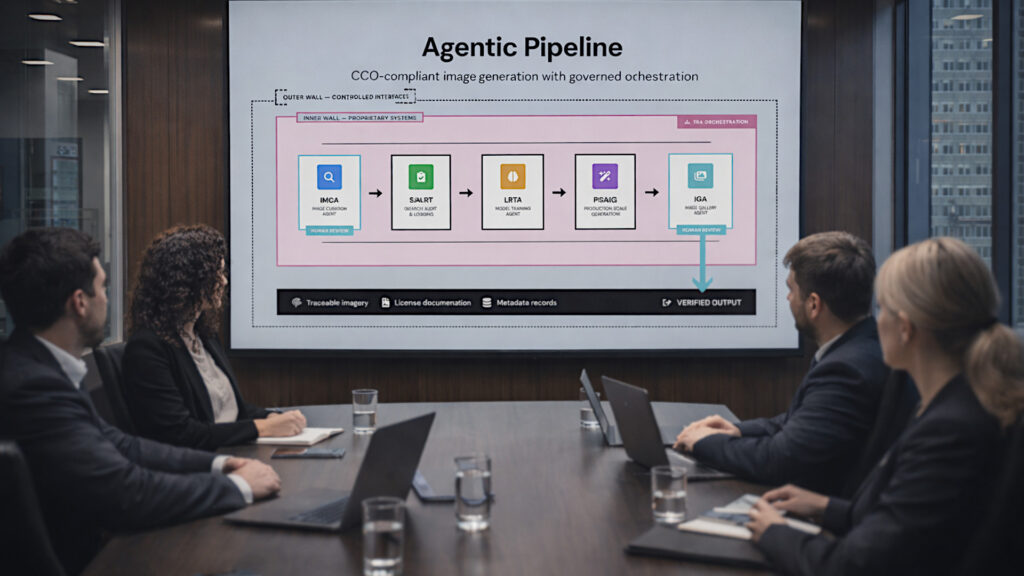
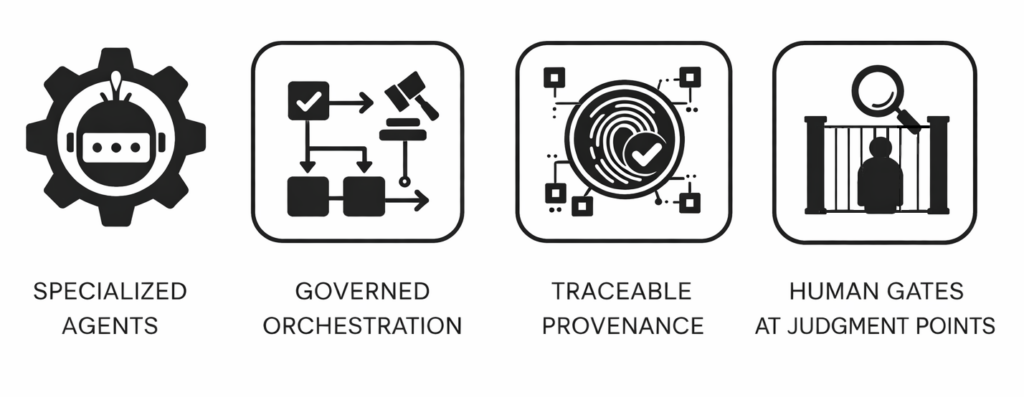
This is the part of the landscape closest to my own work, so I will be direct about the lesson. The defensible position is not “we used AI” versus “we didn’t.” It is whether you can show your work: where the training imagery came from, whether it was used with consent or under a clean license, and whether the audience was told.
Provenance stopped being a compliance footnote and became part of the product. The brands that weather the next backlash will be the ones that can answer “where did this image come from?” without flinching.
Shift two: the storefront itself is starting to dissolve
My 2024 piece assumed a shopper who visits a storefront, even a hyper-personalized one. The most disorienting development since then is that the visit may not happen at all. The shopper increasingly delegates to an agent.
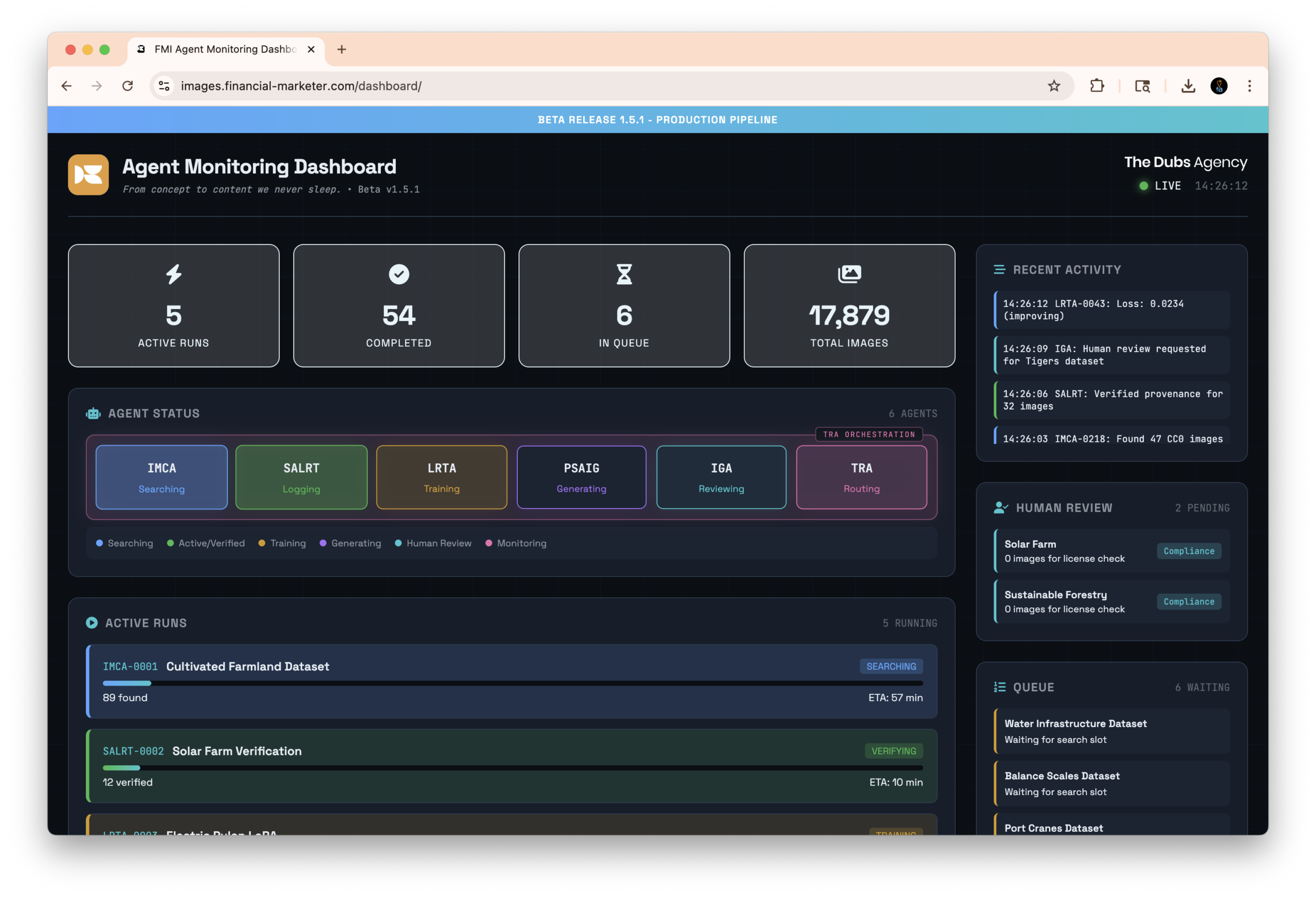
The infrastructure arrived fast. OpenAI introduced an Agentic Commerce Protocol with Stripe; Google launched a Universal Commerce Protocol at NRF in January 2026; Microsoft shipped Copilot Checkout; Shopify rolled out agentic storefronts that let merchants sell inside ChatGPT, Copilot, and Gemini at once. Walmart and OpenAI announced a buy-in-chat partnership in October 2025, and Amazon extended its “Buy for me” capability while pointing its Rufus assistant toward comparison and autonomous purchasing. Shopify has said orders originating from AI-powered search grew roughly fifteen fold year over year.
And yet the reality check is just as instructive. OpenAI quietly paused its Instant Checkout, with fewer than 30 of Shopify’s millions of merchants live, conceding the experience lacked the flexibility it wanted. Walmart reportedly saw in-chat purchase conversion run about three times lower than sending shoppers to its own site. Forrester’s read on the moment was blunt: everyone has the fear of missing out, and nobody has actually figured it out yet.
For anyone building in this space, and I spend most of my week here, the takeaway is unglamorous but clear. The near-term winners are not the brands automating checkout most aggressively. They are the ones making their catalogs, inventory, pricing, and trust signals as readable by machines as by humans. The storefront is becoming an API. Fashion brands that still treat product data as marketing copy, rather than structured source-of-truth data, will simply be invisible when an agent comes shopping.
The map redrew itself, and not only because of technology
My original piece ranked the top online fashion retailers by 2023 sales: Shein at $14.4 billion, Walmart at $12.3 billion, Amazon at $8.4 billion. That snapshot is already a historical document, and the force that dated it was policy, not algorithms.
In 2025 the U.S. ended the “de minimis” exemption that had let sub-$800 parcels enter the country duty-free, the loophole that made the Shein and Temu model viable at scale. Prices rose, both companies warned customers directly, and transactional data showed price-sensitive shoppers migrating toward off-price department stores, secondhand apps, and domestic players. It is a useful corrective to any tech-first narrative: the consumer’s behavior is shaped at least as much by tariff schedules and trade policy as by virtual try-on.
The story so far is mostly digital, but one of the more interesting sustainability bets of 2026 is chemical.
In April, the Bezos Earth Fund committed $34 million to rethink what clothes are actually made of, on the logic that materials and manufacturing account for roughly 80% of fashion’s environmental footprint. The largest grant, $11.5 million, went to Columbia University in partnership with the Fashion Institute of Technology to grow a textile fiber from bacteria fed on agricultural waste: strong and breathable, compostable at end of life, requiring almost no land, and producing no microplastic pollution.
A fiber whose origin is a documented feedstock and a known biological process is provenance pushed all the way down to the molecule. The question the industry asks: “where did this come from?”, is now being asked of the thread itself.
The real divider isn’t AI adoption. It’s digital maturity.
Step back from any single tool and a pattern emerges. The brands getting caught flat-footed and the ones quietly compounding advantage are not separated by whether they use AI. They are separated by how deeply it is woven in.
A useful framing here comes from Browzwear’s digital-maturity work: maturity is not the act of adopting tools, it is integrating them into every part of the business until they drive continuous, scalable impact. Buying the software is the easy part. Rewiring how the organization works around it is the actual transformation.
That work sketches a five-phase climb, and it maps almost too neatly onto the stories above:
- The analog trap. Traditional, siloed processes, no real strategy, digital as an afterthought.
- Reactive experimentation. Isolated pilots run by individual teams, no executive sponsorship, wins that never scale past the team that ran them.
- Intentional progress. A genuine digital strategy appears, often anchored by a dedicated Centre of Excellence, but adoption is still patchy across functions.
- Integrated growth. Leadership-backed, cross-departmental, with digital embedded in day-to-day operations rather than bolted on.
- Digital maturity. Agile, data-driven, customer-centric. Digital is no longer an add-on; it is the core the business runs on.
Seen through that ladder, a lot of last year’s headlines look less like innovation and more like Phase 2 wearing a Phase 5 costume. A splashy AI ad with a near-invisible disclaimer is an isolated pilot optimized for a press cycle, not an integrated practice with disclosure and provenance designed in from the start. The paused in-chat checkout was the same reflex at platform scale: ship the demo, skip the plumbing. Real maturity is comparatively boring. It looks like a manufacturer quietly producing thousands of digital styles a year because the whole organization, not one enthusiastic team, was rebuilt around it.
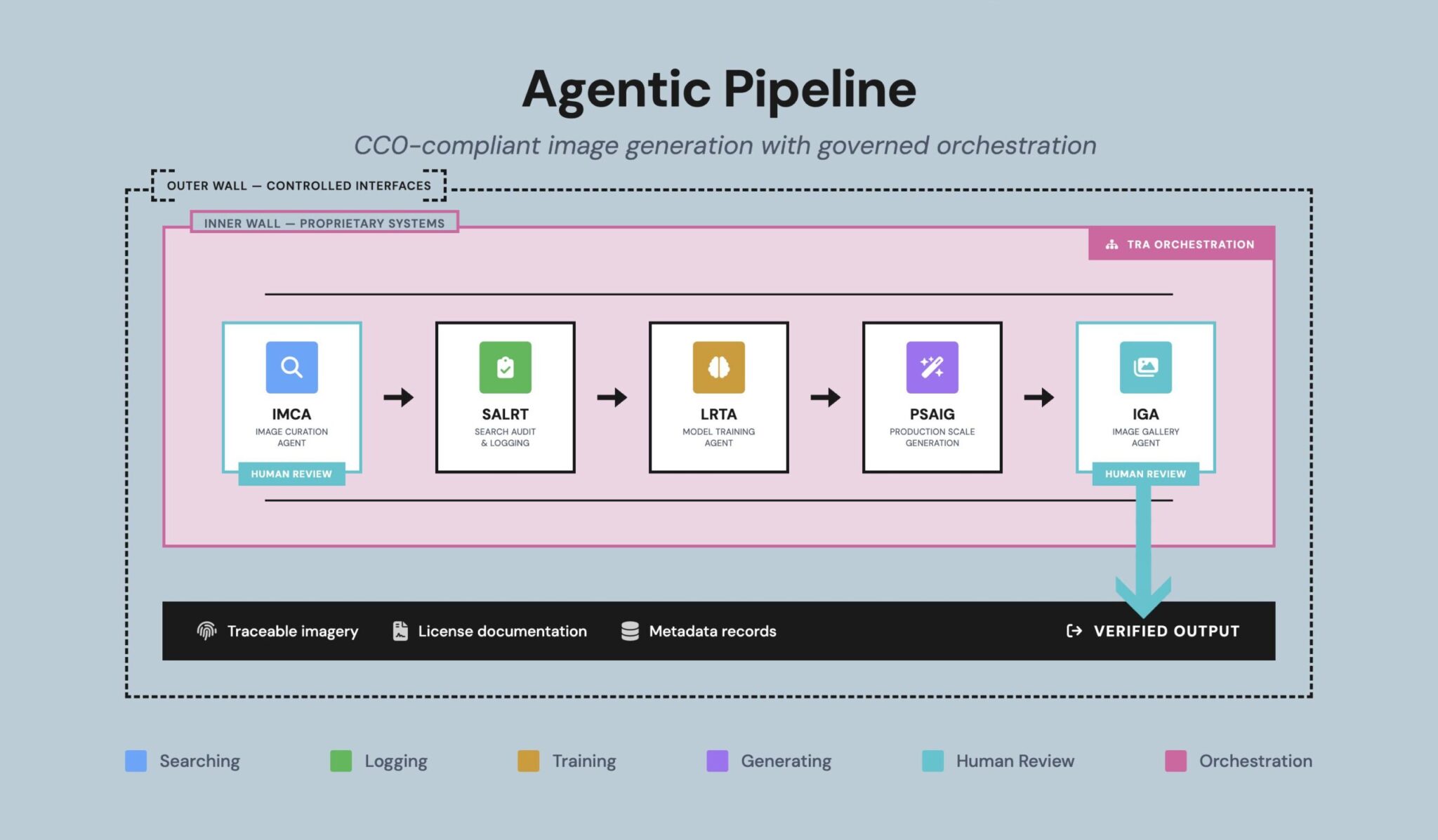
Provenance-clean, properly licensed training data is what lets you use AI imagery without inviting a backlash.
Here is where it connects back to my own throughline, and why I do not treat the ethics question and the agentic-commerce question as separate from this. The discipline that gets you up the maturity ladder, clean integrated data and a single source of truth, is the same discipline that makes you ready for both shifts.
Provenance-clean, properly licensed training data is what lets you use AI imagery without inviting a backlash. Structured, machine-readable product data is what lets an agent actually find and buy what you sell. Disclosure, provenance, and machine-readability are not three separate compliance chores. They are three faces of one mature operation that knows where its data comes from and where it goes.

Field notes from FIT Tech Week: the bleeding edge
I recently attended the Fashion Institute of Technology’s Tech Week event, listening to the founders actually building this layer, and the view from inside is more concrete, and more interesting, than the trend pieces suggest.
The sharpest demonstration came from Emily of Make the Dot, who walked through producing a denim collection called OSSA in roughly the time it usually takes to schedule a fitting. The old playbook she is replacing is familiar: watch what is selling, copy the winning trends, order in enormous quantities, and eat the waste. Her version inverts it.
An agent, “Dot,” aggregated the entire signal chain, from runway to brands to influencers to social to Google search trends, and generated design variations out of the pattern in that data. A human, Nicole, curated, deciding which pieces actually made the collection. Fit was tested digitally, and the agent produced a line sheet specified down to the wash, the whiskers, and the PP spray. Because the supply chain is vertically integrated, cotton to mill to cut-and-sew, a cycle she described as “six plus six” now runs in about four weeks.
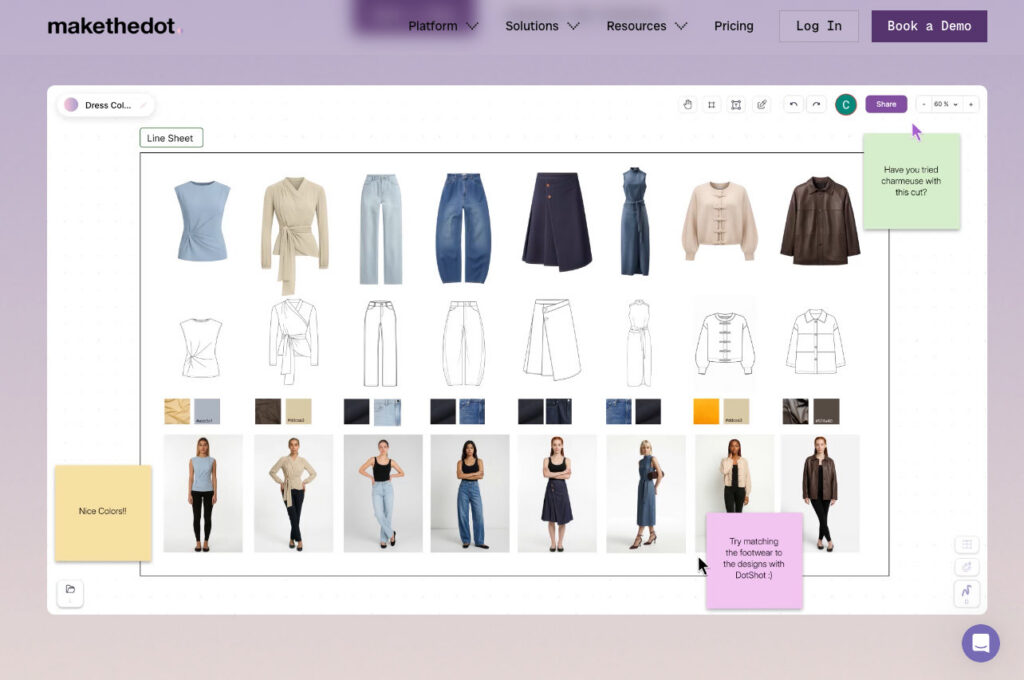
Two of her lines stuck with me. “When making something small is nimble, a bet becomes a test,” she said, describing how a brand can float a social ad to gauge demand before committing a single yard to production. And the one that quietly reframes the whole sustainability conversation: “the path to the least waste also means more time for creativity.” She delivered it wearing the jeans.
That is the optimistic, operational story. The panel I sat in on, “Beyond the Headlines: The Real Ways AI Is Changing Fashion,” moderated by Rachel Sterling of The Pattern Maker and Alternew, pushed on where this goes next, and the founders mostly agreed the change is structural rather than cosmetic.
Franz Tschimben of ALLSIDES was candid that the specifics are hard to predict, but bet that 3D will emerge as a default mode of content creation as the cost of producing it collapses, the same digital-twin logic from earlier in this piece, generalized. Yusan Lin of Mirror Mirror AI described a decentralization of discovery: a world where anyone can be scouted, rather than waiting to be found by a gatekeeper. Sreya Halder of The Mall extended that to creation itself, a world where everyone gets to build their own village and curate it themselves.
Then Sophia Sterling, formerly of Google Creative Lab and now building a stealth venture called Paprika, planted the flag I found most worth carrying home. The company is named for the Diana Vreeland line, “a little bad taste is like a nice splash of paprika,” her argument against the tyranny of no taste at all. Sterling’s pitch is for what lives outside the algorithm: the human, physical, slightly-wrong instinct that recommendation engines flatten on contact.
It is the same tension the rest of this piece keeps circling. Dot can aggregate every signal in the market, but Nicole still decides what is good. The tools democratize who gets to make and be seen, and in the same breath they raise the value of the one thing they cannot generate, a point of view. If the last eighteen months were about proving the machinery works, the bet these founders are placing is that the next eighteen are about taste.
What this means for “the present future”
The sewing machine analogy I leaned on still works, but it needs a second half. The sewing machine made garments faster and cheaper, and in doing so it created entirely new questions about labor, standardization, and who got to call themselves a maker. AI is repeating that pattern at compressed speed across the whole pipeline, from concept render to synthetic model to autonomous checkout. The efficiency is real. So are the questions.
If the 2024 story was “limitless possibilities,” the 2026 story is that the possibilities now carry a price of admission, and that price is maturity: disclosed AI, consented and licensed training data, traceable provenance, and honest, machine-readable product information, all integrated rather than bolted on. The brands and builders who treat that as a constraint will keep getting caught flat-footed. The ones who treat it as the design spec are, I think, the ones who actually inherit the present future.
Joe Skopek is the founder of Velocity Ascent, an AI-first innovation consultancy based in New York and a member of the Leadership Team of the NYC Chapter of the NANDA Project from MIT Media Lab.
Sources and further reading
McKinsey & Company, The State of Fashion 2026: When the rules change (Nov 2025); McKinsey fashion technology outlook on ML adoption (early 2026)
Business of Fashion, on generative AI and virtual try-on (Jan 2026)
FASHN AI, Fashion AI: 7 Key Use Cases in 2026 (AI-generated photography market sizing, Feb 2026)
Browzwear, The Future of Digital Product Development: Trends Shaping Fashion in 2026 (“idea to twin to shelf”); Browzwear, A Digital Maturity Framework for Brands & Manufacturers (five-phase maturity model, MAS Holdings case study)
CNN, AI models in Vogue (Mango and Levi’s context, Jul 2025); Good Morning America / FashionNetwork, on the Guess-Vogue / Seraphinne Vallora campaign (Aug 2025)
Fast Company, Shop ’til you bot (agentic commerce, Instant Checkout pause, 2026); commercetools, The Agentic Commerce Radar (protocols, Walmart conversion data, 2026); Digital Commerce 360 (platform strategies, Apr 2026)
WWD and Morning Consult, on the end of de minimis and the Shein/Temu impact (2025); Business of Fashion, Will the End of De Minimis Kill the Shein Haul? (Jul 2025)
Bezos Earth Fund, Reinventing Clothes: $34 Million in Grants (Apr 2026); Columbia Engineering, on the $11.5M Columbia/FIT bacterial-fiber grant (Apr 2026)
FIT Tech Week (2026), author’s field notes: panel “Beyond the Headlines: The Real Ways AI Is Changing Fashion” (moderator Rachel Sterling, The Pattern Maker / Alternew; panelists Franz Tschimben, ALLSIDES; Yusan Lin, Mirror Mirror AI; Sreya Halder, The Mall; Sophia Sterling, Paprika), and the Make the Dot presentation (Emilie Ho, co-founder and CEO). Vreeland quote from D.V. (1984)