Analyze Everything. Read Nothing. A court-ordered constraint became the design brief for a new class of agentic pipeline — built for legal, compliance, and regulated document work at any scale.
The most interesting systems get built under impossible constraints.
In early 2026, Velocity Ascent was engaged to support a high-volume foreign language legal document translation project under active litigation. A New York City translation company had been retained by an international law firm operating under a court-issued protective order. The requirement was precise and non-negotiable: produce an accurate translation scope and cost estimate across thousands of pages of scanned source documents — without any member of the project team reading the underlying content.
Velocity Ascent designs bespoke agentic systems that maximize what AI can do autonomously – while staying precisely within the legal, regulatory, and compliance requirements specific to each client’s situation.
The documents existed. The estimate had to be produced. The protective order governed exactly what could and could not be touched. The gap between those two facts is where the engineering began.
Velocity Ascent designs bespoke agentic systems that maximize what AI can do autonomously — while staying precisely within the legal, regulatory, and compliance requirements specific to each client’s situation. The system described here was built for one engagement. The architecture behind it is built for any.
What emerged from that constraint is an agentic pipeline we believe has implications well beyond a single translation project — for any organization that needs to analyze, classify, or route sensitive document corpora without exposing their contents to human reviewers.
The Compliance Problem Nobody Talks About: What happens when the requirement is to analyze without access?
Most regulated document workflows assume that the people building the pipeline can see what’s inside it. Translation firms scope work by reading samples. Legal teams estimate review hours by examining files. Compliance officers assess risk by opening documents.
Court orders, privilege designations, data sovereignty rules, and cross-border regulatory requirements increasingly break that assumption. The analyst cannot read the document. The estimator cannot open the file. But the work still has to be scoped, quoted, and delivered accurately.
Traditional approaches fail here in a specific way: they treat “review the documents” and “estimate the scope” as a single inseparable step. If you cannot do the first, you cannot do the second. The project stalls, costs inflate, or the constraint gets quietly worked around in ways that create downstream exposure.
Agentic pipelines solve this by separating observation from comprehension. A properly designed agent can characterize a document — page count, word density, language composition, structural complexity, document type — without surfacing a single line of content to any human reviewer. The observation layer and the content layer never meet.
Agentic Architecture: The Double Garden Wall Applied to Document Intelligence
The Double Garden Wall is an architecture we first developed for our ethical AI image generation tool — a system that needed to guarantee CC0 provenance on every training asset without relying on human memory or manual spot-checks. The principle transfers directly to regulated document handling.
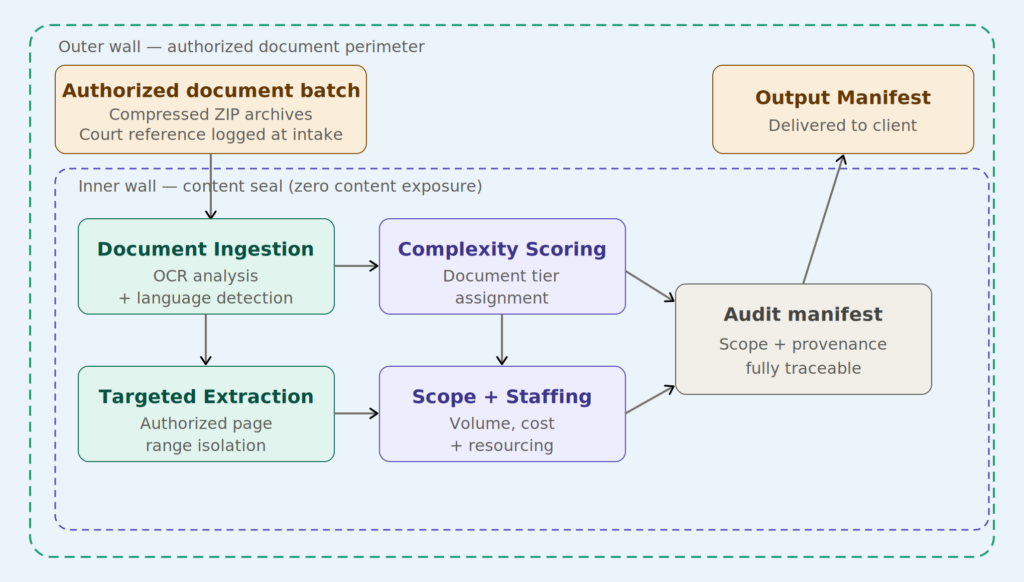
Double Garden Wall architecture: specialized agents operating within layered compliance boundaries, where every document is characterized structurally and no content crosses to any human reviewer.
The outer wall defines what enters the system at all: only authorized document batches, governed by a court reference number logged at intake. Nothing flows in without an audit trail attached to it. The inner wall ensures that what exists inside the system — the actual document content — never crosses to the analysis agents. Statistical signals are sufficient. Page counts, word densities, language composition, Bates-to-page mappings, and structural classification are all derivable without any agent reading the underlying text.
The architecture employs two core agents working in sequence:
The Batch Analyzer ingests a ZIP archive of scanned documents and runs OCR analysis across every file. It classifies each document by legal complexity tier — standard, specialist, or legal-high — based on structural signals: form density, mixed-language composition, handwritten elements, embedded stamps, and regulatory formatting patterns. It produces a structured manifest with word count estimates, page totals, and staffing recommendations. No human reviewer sees any document content. The agent produces numbers and classifications from signal, not from reading.
The Batch Extractor handles partial-translation requests, which are common in litigation contexts where only specific Bates-numbered page ranges are required. Rather than requiring a human to manually locate and pull pages from multi-hundred-page archive PDFs, the extractor maps document IDs to physical page positions and organizes extracted pages into structured output folders ready for translator handoff. The mapping logic is deterministic: the physical page equals the requested ID minus the first ID in that file. There is no guesswork, and no human touches the content to produce the extraction.
Together, these agents answer the core question: how do you scope work you are not permitted to see?

A Live Production Case
The engagement in question involved four document batches totaling thousands of pages of foreign language legal materials from a multi-decade archive. Documents ranged from formal organizational correspondence and regulatory licensing forms to handwritten authorization letters, financial tables, grant applications, and certificates.
Every document was a scanned image PDF — no text layer, no searchable content. The pipeline had to run OCR, classify complexity, map Bates IDs, and produce a scope estimate accurate enough to serve as the basis for a formal translation services agreement — all without any member of our team reading a single document.
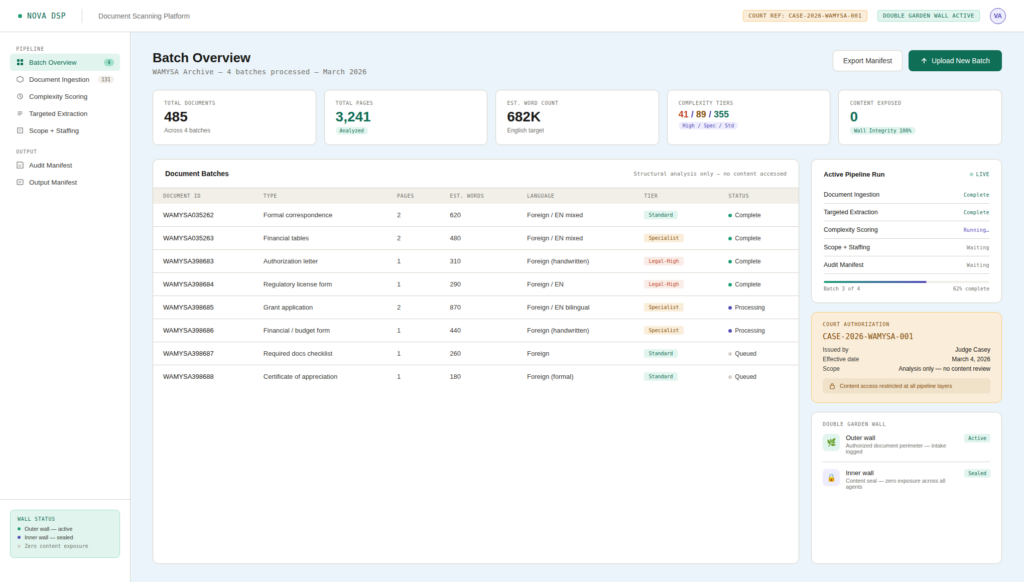
Nova DSP platform interface: real-time pipeline visibility across document ingestion, complexity scoring, and scope generation — with court authorization tracking, agent-by-agent run status, and a live wall integrity monitor confirming zero content exposure at every layer.
The output from the Batch Analyzer provided page counts, estimated word counts, and per-document complexity classifications that allowed the translation firm to staff the engagement correctly: how many legal-specialist translators were required, how many standard-tier translators could handle the lighter materials, what a realistic daily delivery cadence looked like, and what the full project investment would be.
The Batch Extractor then handled the partial-document requests that arrived as the engagement progressed — court-specified page ranges that needed to be pulled, organized, and handed off to translators without any bulk export of content that fell outside the authorized scope.
The audit trail for the entire engagement is complete. Every document batch has a court reference number attached to its intake record. Every OCR pass is logged. Every classification decision is traceable to the signals the agent used to make it. If the protective order is ever challenged, the record demonstrates exactly what was accessed, when, by which process, and what output it produced.
That kind of defensibility is not a feature you add to a pipeline after the fact. It has to be designed in from the first line.
ELEVATOR PITCH:
Regulated industries face a specific class of problem that general-purpose AI tools are not designed to solve — analyzing sensitive document corpora without exposing content to unauthorized reviewers. Agentic pipelines built on a Double Garden Wall architecture handle this by separating observation from comprehension: agents characterize documents through structural signals without any human or downstream system ever accessing the underlying content. The result is an accurate, auditable scope — produced under constraint, defensible under review.
Why the C-Suite Should Care
The Nova Languages engagement is a template, not an edge case.
Every organization that handles regulated documents — legal practices, financial institutions, healthcare systems, government contractors, compliance functions — operates under some version of the same constraint: certain materials cannot be broadly accessed, but decisions still have to be made about them. What are they? How many are there? How complex are they? What will it cost to process them? How do we route them to the right people?
“Every organization that handles regulated documents operates under some version of the same constraint: certain materials cannot be broadly accessed.”
Today, most organizations answer those questions through manual sampling, senior reviewer time, and informed estimation. That approach scales poorly, introduces inconsistency, and creates exposure every time a document is touched by a reviewer who should not have seen it.
C-suite leaders should evaluate agentic document intelligence against three questions that apply regardless of industry or document type:
1. Can the system produce accurate scope estimates without creating unauthorized access records?
2. Can every classification decision be traced back to the specific signals that drove it — not to a reviewer’s recollection?
3. When regulatory scrutiny arrives, can the system demonstrate what was done, when, by which process, and with what authorization?
The answer to all three, for a properly designed agentic pipeline, is yes by construction — not yes in principle, subject to human discipline.
The firms that recognize this distinction early will move faster, engage more confidently in document-intensive regulated work, and carry significantly less risk when the oversight questions inevitably come.
THE BOTTOM LINE
Agentic pipelines for regulated document work are not about processing documents faster. They are about processing documents correctly — within constraint, with full traceability, without the exposure that manual workflows introduce every time a human reviewer opens a file they should not have. For legal practices, compliance functions, and any organization operating under court order, data sovereignty rules, or privilege designations, that combination of analytical capability and content containment is not a competitive advantage. It is the operating standard the work requires.
Velocity Ascent builds AI-powered solutions for regulated industries. We specialize in agentic pipeline architecture, ethical AI sourcing, and production-scale document intelligence with full provenance tracking.